The course Creative Applications of Deep Learning with TensorFlow lead by Parag Mital was providing a good view into different aspects of AI and neural networks like supervised and unsupervised learning, convolutional networks or autoencoders. We also spent a good time playing with the functionality of tensorflow to create deep dreams, guided dreams and other image based operations. For me it was also a good chance to practice Python. The course was using a lot of existing databases and functions to let you focus on network parameters for a better understanding of the underlying principle without having to write everything yourself. I was pregnant at that time so I gladly used the existing resources to be able to finish the course, but I have an idea for which I want to create my own network – I hope to get this done someday. Until then, here are some results of the image based tinkering we have been doing during the course. Enjoy.
Disclaymer This is my first applied contact to machine learning. Explanations might be inaccurate or false and the results not perfect. Please feel free to correct me.
Network painting
One of the first task was to let the network redraw an image “from memory” after learning a bit about it. The first image is the reference (a friend and I happily eating pasta), the second and the third image are the paintings of the network – more abstract depending on the chosen parameters. The gifs show the iteration steps of the process.
-
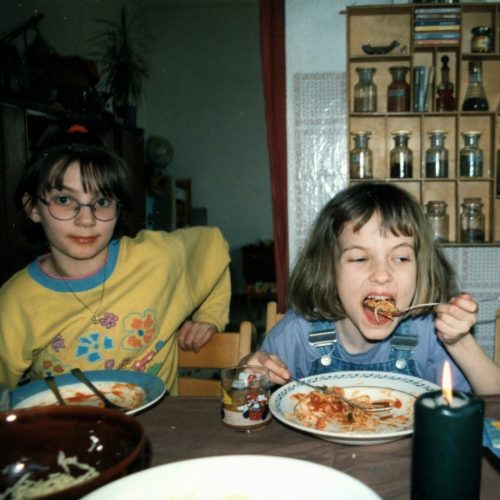
- Original
-

- Drawing #1

-

- Drawing #2

The next test uses more images at once, my dataset contained some pictures of fencers. It shows a first attempt to sort the set and it successfully separated rotated images from the others. The other two images represent results of a network painting based on the dataset (but only those images with black backgrounds behind the fencers). The last gif contains 10 prediced frames at the end (frames without a reference/input image). The resulting animation appears as a painted recording of a fight even though the input images don't represent a sequence. The predicted frames let the fencers vanish in fire, how dramatic is that..
-

- Sorted dataset

-

- Network painting fencers

-

- Network painting fencers with 10 prediced frames at the end

Autoencoder
This autoencoder was also trained with the fencers (unsupervised). The most inner layer of the encoder assigns all inputs a two dimensional value which can be used to reorder the images positioning similar images closer to each other (second image). The background is unsurprisingly the most dominant sorting feature. If you decode the same inner layer activations of the encoder you get the third image (I guess, it's been a while) - a reconstruction of the original based on the knowledge of the autoencoder. With the decoder one can generate a representation of the network (image 4).
-

- Training set for the autoencoder

-

- Sorted by encoder

-

- Reconstruction of input dataset

-

- Representation of autoencoder network

Deep Dreams
Tensorflow can be used to produce deep dreams my amplifying objects in an image the network knows from an extensive supervised training set. One can also let an image dream of another image..
-

- Basic Deep Dream

-

- Fencers dreaming of sky

-

- Sky dreaming of fencers

.. or use another image as a style guide to draw the input image in the same manner.
-

- Input image

-

- Style

-

- Result

VAEGAN
Generative Adversarial Networks (GAN) consist of a generator (like the decoder of the autoencoder) that generates images from a feature vector and a discriminator that should be able to tell whether an input is real or generated. VAEGANS are GANs combined with Variational Auto-Encoding which somehow helps working with features that the autoencoder is trained to recognize - I can't tell you more because I didn't get it, but I was able to produce smiling cats.

Keep dreaming
As already mentioned, I was a bit limited in time so I played around with deep dreams for my final project. Here it is along with two other deep dream clips I produced. The last one is about clocks which reminds me to go to bed. Sweet.. you know what.
PS: The course material is completely accessible on github! Awesome right?